Мы используем cookies для корректной работы сайта и подключаем аналитику (Яндекс.Метрика), чтобы понимать, что улучшать
Мониторинг распределённой ИТ-инфраструктуры
- Единый центр контроля серверов, СХД, сети, филиалов, серверных, ЦОД и бизнес-сервисов. Настроим мониторинг, полезные уведомления, дашборды, пилотный контур и безопасную архитектуру сбора метрик
- Первый шаг — демо-стенд. Покажем работающий дашборд, обсудим вашу архитектуру и предложим пилотный контур: например, серверная / ЦОД + 1–2 филиала + критичные бизнес-сервисы.
от 40 000 ₽/за внедрение пилотного контура
Итоговая цена зависит от объема, состава и требований контура

Когда нужен мониторинг распределённой ИТ-инфраструктуры
Решение подходит, если у компании несколько площадок, а ИТ-команда не видит инфраструктуру целиком: часть сервисов находится в головном офисе, часть — в филиалах, часть — в серверных или ЦОД, а пользователи первыми сообщают о сбоях.
| Ситуация | Что даёт мониторинг |
|---|---|
| 🖥️ Несколько серверных, филиалов или удалённых офисов | Единый дашборд по всем площадкам, серверам, СХД, сети и сервисам. |
| ⚠️ О сбоях сообщают пользователи | Система фиксирует недоступность, деградацию и аппаратные риски до массовых обращений. |
| 🔎 Сложно понять причину инцидента | Быстрее видно, где проблема: сервер, СХД, канал связи, VPN, сеть, провайдер, 1С или приложение. |
| 🔔 Много ложных алертов | Настраиваются зависимости, уровни критичности и правила эскалации, чтобы уведомления помогали, а не создавали шум. |
| 📊 Нужно показывать руководству SLA и доступность | Формируются понятные отчёты по доступности, инцидентам, проблемным площадкам и стабильности сервисов. |
Что контролирует решение
Мониторинг Центр собирает технические метрики и события из распределённой ИТ-среды и показывает состояние инфраструктуры в едином интерфейсе.
| Контур | Что мониторим |
|---|---|
| 🖥️ Серверы Windows / Linux | CPU, память, диски, RAID, доступность узлов, аппаратные датчики, журналы событий, критичные службы. |
| 💾 СХД / NAS / хранение данных | Контроллеры, дисковые группы, производительность чтения/записи, деградация подсистем хранения. |
| 🌐 Сеть, VPN и каналы связи | Маршрутизаторы, коммутаторы, межсетевые экраны, точки доступа, задержки, потери, доступность каналов и связность площадок. |
| ☁️ Виртуализация и кластеры | Гипервизоры, виртуальные машины, ресурсы, доступность кластеров, деградация производительности. |
| 📦 1С, CRM, почта и внутренние сервисы | Доступность бизнес-сервисов, время отклика, ошибки, состояние критичных приложений по филиалам и удалённым объектам. |
| ⚡ Инженерные системы серверных | ИБП, климат, питание, температурные показатели и другие параметры, если оборудование поддерживает сбор метрик. |
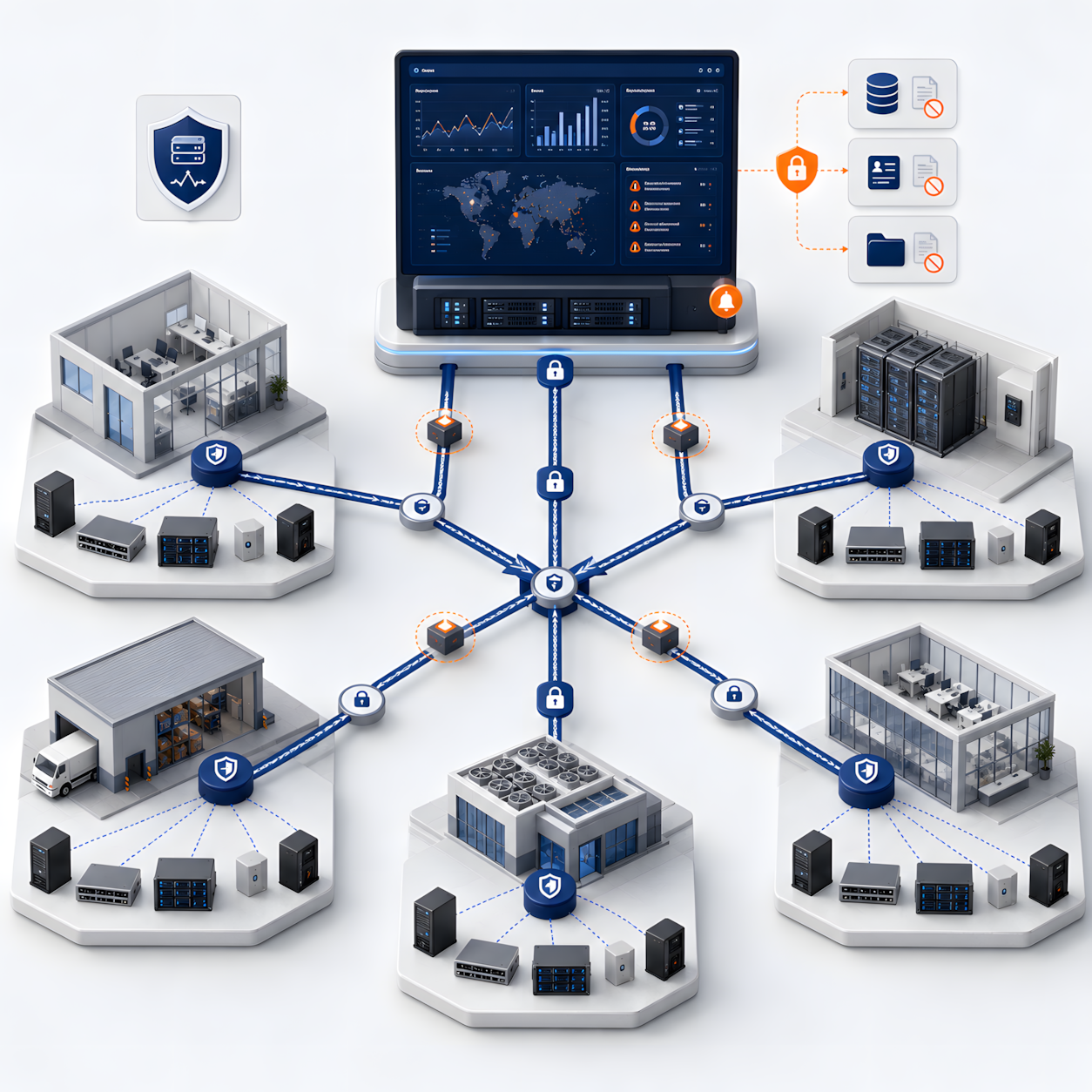
Архитектура мониторинга: как собираются метрики
Для распределённой инфраструктуры важно не просто установить систему мониторинга, а правильно спроектировать архитектуру сбора данных: центральный сервер, proxy или локальные сборщики на площадках, агенты, безагентный сбор, уведомления и безопасную передачу метрик.
Типовая схема
- Центральный контур мониторинга — единый интерфейс, дашборды, история событий, отчёты и правила уведомлений.
- Площадки и филиалы — серверные, офисы, склады, удалённые объекты, ЦОД или локальные серверные.
- Сбор данных — агенты, proxy, SNMP, IPMI, WMI, API, syslog и другие механизмы в зависимости от оборудования и сервисов.
- Безопасная передача метрик — VPN/TLS, разграничение прав, минимально необходимые доступы, передача технических метрик без коммерческих данных.
- Оповещения — email, стандартный мессенджер, корпоративный мессенджер, Service Desk / ITSM или другой согласованный канал.
Итоговая архитектура подбирается под вашу инфраструктуру: количество площадок, качество каналов связи, типы оборудования, требования ИБ и текущие процессы ИТ-службы.
Как мы убираем шум и ложные алерты
Мониторинг бесполезен, если инженеры получают сотни уведомлений и перестают на них реагировать. Поэтому при внедрении важно настроить не только сбор метрик, но и логику событий.
- Настраиваем уровни критичности - информационные события, предупреждения, аварии и критичные инциденты разделяются по приоритету.
- Учитываем зависимости - если недоступен корневой маршрутизатор, система не должна отправлять десятки вторичных уведомлений по узлам за ним.
- Настраиваем эскалацию - разные события уходят разным ответственным: сетевым инженерам, администраторам серверов, ИБ или руководителю ИТ.
- Обкатываем правила на пилоте - проверяем реальные срабатывания, корректируем пороги и убираем лишний шум до масштабирования.
Цель — не красивые графики, а полезные уведомления: что случилось, где именно, насколько критично и кому нужно реагировать.

Безопасность мониторинга между филиалами
При мониторинге распределённой инфраструктуры ИБ важна не меньше, чем функциональность. Мы проектируем сбор данных так, чтобы не создавать лишние риски между площадками.
- Передаются технические метрики и статусы, а не коммерческие данные.
- Используются минимально необходимые права для сбора данных.
- Передача может быть организована через VPN/TLS и согласованные сетевые правила.
- Для удалённых площадок возможны локальные proxy / сборщики метрик.
- Доступы, роли и ответственность фиксируются в документации.
Если канал связи нестабилен
Для филиалов и удалённых площадок может использоваться локальный сбор и буферизация данных. При кратковременном обрыве канала телеметрия не теряется, а передаётся в центральный контур после восстановления связи.
Что получает заказчик после запуска
- 📊 Единый дашборд по филиалам, серверным, ЦОД, серверам, СХД, сети и бизнес-сервисам.
- 🔔 Полезные уведомления о сбоях, деградации, перегрузке ресурсов и аппаратных рисках.
- 🧭 Быструю локализацию проблем — видно, где причина: площадка, канал, сервер, СХД, сеть или сервис.
- 📈 Отчёты по SLA и доступности для ИТ-службы и руководства.
- 🧾 Документацию по архитектуре, подключённым объектам, шаблонам, триггерам и правилам уведомлений.
- 👨💻 Обучение команды — показываем, как читать дашборды, обрабатывать события и добавлять новые объекты.
- 🛠️ План масштабирования — какие площадки, сервисы и устройства подключать следующими этапами.
После внедрения система не должна быть «чёрным ящиком». Ваша ИТ-команда получает доступы, документацию, регламенты и понимание, как сопровождать мониторинг дальше.
Как запускаем проект
| Этап | Что делаем |
|---|---|
| 1️⃣ Демо и первичная консультация | Показываем демо-дэшборд, обсуждаем инфраструктуру, площадки, критичные сервисы и текущие проблемы. |
| 2️⃣ Выбор пилотного контура | Определяем, что подключить в пилот: серверная / ЦОД, 1–2 филиала, сетевое оборудование, 1С, CRM, почта или другие сервисы. |
| 3️⃣ Проектирование архитектуры | Определяем центральный сервер, proxy/агенты, протоколы сбора, каналы передачи метрик, роли доступа и требования ИБ. |
| 4️⃣ Настройка мониторинга | Подключаем объекты, настраиваем шаблоны, триггеры, зависимости, дашборды, уведомления и правила эскалации. |
| 5️⃣ Обкатка и корректировка алертов | Проверяем реальные срабатывания, убираем ложный шум, корректируем пороги и сценарии уведомлений. |
| 6️⃣ Передача в эксплуатацию | Передаём документацию, доступы, регламенты и обучаем вашу ИТ-команду работе с системой. |
Форматы запуска
| Формат | Когда подходит | Результат |
|---|---|---|
| Демо | Нужно быстро понять, как выглядит работающая система и какие дашборды можно получить. | Показываем интерфейс, сценарии алертов, структуру дашбордов и возможный пилотный контур. |
| Пилот | Нужно проверить решение на реальной инфраструктуре без масштабного проекта на старте. | Подключаем ограниченный контур: серверная / ЦОД, 1–2 филиала, сеть и несколько критичных сервисов. |
| Проект внедрения | Нужно построить полноценный центр мониторинга для всей распределённой инфраструктуры. | Проектируем архитектуру, подключаем площадки, настраиваем алерты, дашборды, отчёты и передачу в эксплуатацию. |
Стоимость внедрения мониторинга ИТ-инфраструктуры
Стоимость зависит от количества площадок, серверов, сетевых устройств, СХД, бизнес-сервисов, требований к безопасности, глубины дашбордов, интеграции с Service Desk / ITSM и необходимости дальнейшего сопровождения.
Чтобы не запускать большой проект «вслепую», можно начать с демонстрации или пилотного контура на ограниченной части инфраструктуры: серверная / ЦОД, 1–2 филиала, несколько критичных сервисов и сетевых устройств.
| Формат | Ориентир стоимости | Что входит |
|---|---|---|
| Демо - дэшборд | Бесплатно | Покажем пример работающего мониторинга, типовые дашборды, сценарии алертов и обсудим, как это может лечь на вашу инфраструктуру. |
| Пилотный контур | от 40 000 ₽ без НДС | Подключение ограниченного контура: серверная или ЦОД, 1–2 филиала, несколько серверов, сетевых устройств и критичных сервисов. Настройка базовых дашбордов, уведомлений и проверка сценариев алертов. |
| Базовое внедрение | от 180 000 ₽ без НДС | Проектирование архитектуры мониторинга, подключение нескольких площадок, серверов, сети, СХД или NAS, настройка дашбордов, триггеров, уведомлений и первичная документация. |
| Распределённый контур | от 350 000 ₽ без НДС | Мониторинг филиалов, серверных, ЦОД, каналов связи, сетевого оборудования, СХД, бизнес-сервисов, proxy/агентов, локального сбора метрик, сложных зависимостей и отчётов по SLA. |
| Сопровождение после запуска | от 20 000 ₽/мес. без НДС | Поддержка системы мониторинга, корректировка алертов, добавление новых объектов, обновление дашбордов, консультации ИТ-команды и контроль стабильности работы. |
Цены указаны как ориентиры «от» для типовых сценариев и не являются публичной офертой. Итоговая стоимость зависит от количества объектов мониторинга, сложности инфраструктуры, требований к ИБ, интеграций, необходимости выезда и формата сопровождения.
Для точной оценки достаточно прислать количество площадок, серверов, сетевых устройств, СХД, критичных сервисов и описание текущих проблем: ложные алерты, отсутствие единого дашборда, нестабильные каналы, ручная диагностика или долгий поиск причин сбоев.
Запросите демо или пилот: покажем работающий контур, уточним ваш сценарий и подготовим предварительную оценку.

Частые вопросы:
Мы можем настроить Zabbix сами. Зачем нужен интегратор?
Самостоятельная настройка часто превращается в долгий внутренний проект: нужно продумать архитектуру, proxy, шаблоны, триггеры, зависимости, дашборды, уведомления, роли доступа и регламенты. СИНТО помогает быстрее собрать рабочий контур мониторинга и передать его вашей команде с документацией и обучением.
Можно ли начать не со всей инфраструктуры, а с пилота?
Да. Обычно пилот строится на ограниченном контуре: серверная или ЦОД, 1–2 филиала, несколько серверов, сетевых устройств и критичных сервисов. После пилота можно оценить пользу, скорректировать алерты и масштабировать решение.
Какие системы и протоколы можно использовать?
Подход зависит от вашей инфраструктуры. Возможен агентский и безагентный сбор данных, SNMP, IPMI, WMI, API, syslog, proxy/агенты и другие механизмы. На этапе обследования определяем, какие методы безопаснее и эффективнее для ваших площадок.
Что будет, если канал связи с филиалом нестабилен?
Для удалённых площадок можно использовать локальный сбор и буферизацию данных. Если канал временно недоступен, телеметрия сохраняется локально и передаётся в центральный контур после восстановления связи.
Будут ли передаваться коммерческие данные?
Нет, для мониторинга передаются технические метрики, статусы и события. Архитектура передачи данных, права доступа, каналы связи и требования ИБ согласуются до внедрения.
Как избежать сотен ложных алертов?
Настраиваем зависимости, уровни критичности, пороги, корреляцию событий и правила эскалации. На пилоте проверяем реальные срабатывания и убираем лишний шум до масштабирования.
Можно ли интегрировать уведомления с нашими процессами?
Да. Уведомления можно направлять в email, мессенджер, корпоративный мессенджер, Service Desk / ITSM или другой согласованный канал. Сценарии интеграции определяются на этапе проектирования.
Сможет ли наша ИТ-команда сопровождать систему самостоятельно?
Да. После внедрения передаём документацию, доступы, описание архитектуры, шаблоны, триггеры, правила уведомлений и обучаем вашу команду работе с системой.
Кратко об услуге
Мониторинг распределённой ИТ-инфраструктуры СИНТО - это проектирование и настройка единого центра контроля для серверов, СХД, сети, филиалов, серверных, ЦОД, 1С, CRM, почты и внутренних бизнес-сервисов.
Услуга подходит компаниям с несколькими площадками, филиальной сетью, удалёнными офисами, складами, серверными и критичными ИТ-сервисами. Решение помогает обнаруживать инциденты раньше пользователей, сокращать время диагностики, снижать количество аварийных работ и формировать отчёты по SLA для руководства.